
垃圾收集算法是内存回收的方法论。
垃圾收集器是内存回收的具体实现。
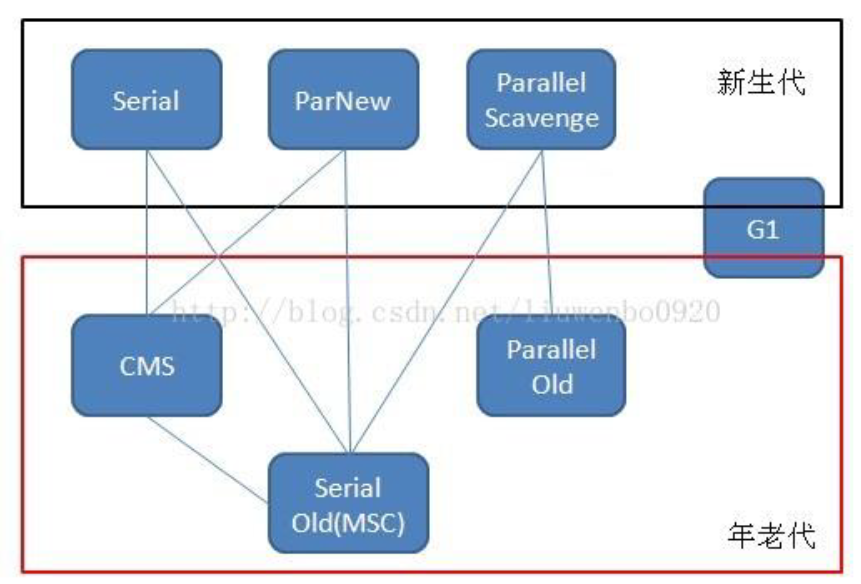
连线代表可以组合搭配使用
概念整理
- jvm的server模式和client模式区别可以点击参考此博客内容
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个CPU上。
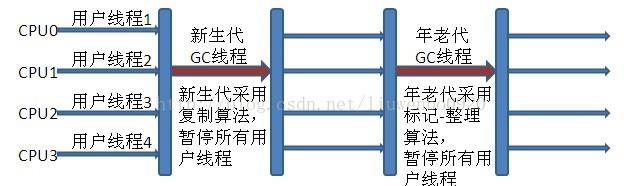
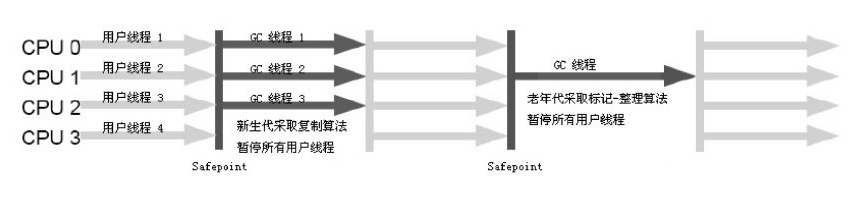
新生代垃圾收集器使用标记-复制算法
Serial(Client模式下的默认的)
单线程垃圾回收,回收时会暂停所有线程。(Stop The World)
图为serial+serial old
ParNew(Server模式下的默认的)
- Serial+多线程并行实现的
- 默认开启和CPU相同的线程数
通过以下参数限制数量
1-XX:ParallelGCThreads相比Serial缺点:
单CPU下比Serial慢,因为有线程交互的开销
Parallel Scavenge
多线程并行复制算法,重点是关注程序达到一个可控制的吞吐量。
吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
通过以下参数控制12345#控制最大垃圾收集停顿时间-XX:MaxGCPauseMillis#直接设置吞吐量大小(0~100)-XX:GCTimeRatio
比起ParNew多一个特点就是自适应调节策略1-XX:+UseAdaptiveSizePolicy
当这个参数开启后,就不需要设定以下参数,只需要设定堆最大内存即可-Xmx
- -Xmn(新生代大小)
- -XX:SurvivorRatio(Eden与Servivor比例)
- -XX:PretenureSizeThreshold(晋升老年代年龄)
老年代垃圾收集器使用标记-整理算法
Serial Old(client模式下的默认的)
是Serial收集器的老年代版本
Parallel Old
图为parallel scavenge/parallel old(注重吞吐量以及CPU资源敏感的场合)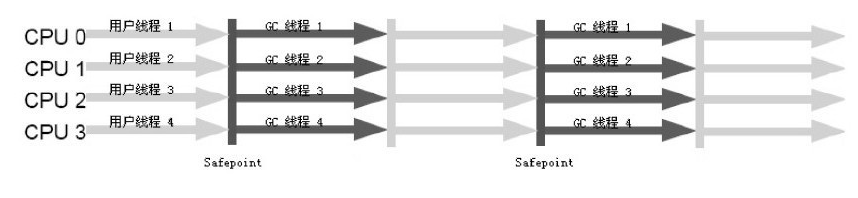
是Parallel Scavenge收集器的老年代版本
G1(Garbage First)
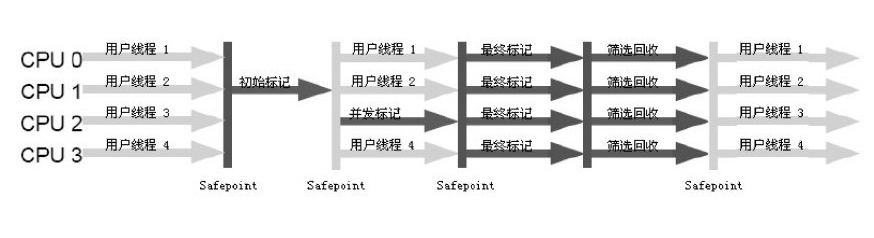
直接将堆结构分成极其多个区域,每个区域都可以充当Eden区、Survivor区或者老年代中的一个。
优先回收死亡对象较多的区域。
步骤:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
使用多线程标记-清除算法
CMS(Concurrent Mark Sweep)
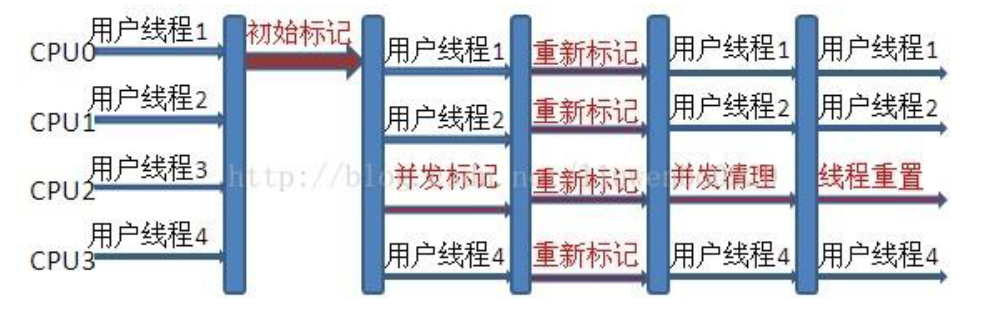
CMS 关注点是尽可能地缩短垃圾收集时用户线程的停顿时间
需要以下4个步骤:
- 初始标记(stop the world)
只是标记一下GC Roots能直接关联的对象,速度很快 - 并发标记
进行GC Roots跟踪的过程和用户线程一起工作 - 重新标记(stop the world)
为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录 - 并发清除
清除GC Roots不可达对象和用户线程一起工作
缺点:
- cpu资源敏感
- 无法清理浮动垃圾
由于CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS无法在当次收集中处理掉它们,只好留待下一次GC时再清理掉。 - 出现大量的空间碎片
读后感笔记来自周志明的《深入理解Java虚拟机(第2版)》
